3–dimensional cube array parallel scaling¶
This is a 3–dimensional case, solfec/examples/hybrid–solver3, of the family of 1,2 and 3–dismenional examples, demonstrating applications of the HYBRID_SOLVER to hybrid, Parmec–Solfec-1.0 based, arrays of cubes subject to an acceleration sine dwell signal. The specifcation of geomery and material data are exactly generalized from the 2–dimensional counterpart. The solfec/examples/hybrid–solver3 directory contains:
README – a text based specification of the problem
hs3–parmec.py – including the Parmec input code
hs3–solfec.py – including the Solfec-1.0 input code
hs3–state–1.pvsm – ParaView state for animation 1
hs3–state–2.pvsm – ParaView state for animation 2
- 1(1,2)
ParaView animation based on the state file hs3–state–1.pvsm. The see–through array is modeled in Parmec: rotations are restrained and spring–dashpot elements, emulating contact, are insered at the centres of faces of neighbouring cubes. The solid 3x3 inner arrays is modeled in Solfec-1.0: hexahedral finite elements are used and contact interactions are modeled via a non–smooth Signorini–Coulomb law
- 2(1,2)
ParaView animation based on the state file hs3–state–3.pvsm. Parmec spring forces are visualised on the left hand side. On the right hand side, in the Solfec-1.0 model, the spheres symbolizse detected contact points, while their colors depict the magnitudes of the contact forces.
Animations 1 and 2 are based on \((M+N+M)\times(M+N+M)\times(M+N+M)\) arrays, where \(M = 5\) and \(N = 3\). To test parallel scaling, a larger model, with \(M = 5\) and \(N = 20\), was used. This resulted in the total number of 27000 bodies, of which the inner 8000 was modeled using \(2\times2\times2\) finite element meshes in Solfec-1.0. The total number of Solfec-1.0 bodies was 10408, which includes the additional layer of 2408 rigid bodies, providing an overlap with the Parmec submodel. In order to provide a stiffer support for the larger, \(20\times20\times20\), inner array of bodies, the spring stifness and damping coefficients in the Parmec submodel were multiplied by 10. One second runs with time step of 5E-4s were performed. None of the remaining parameters of the model were changed. Animation 3 depicts the motion of this larger model.
- 3
ParaView animation of the 30x30x30 array with N=20. A part of the Parmec model is hidden so that the inner 20x20x20 Solfec-1.0 array can be seen; this also helps to visualize interaction between the Parmec and Solfec-1.0 submodels.
Table 28 summarises the parallel runtimes. Total speedup of 3.87 was achieved using 192 CPU cores, versus the baseline single cluster node run on 24 CPU cores. Intel Xeon E5–2600 CPU based nodes were used, with 24 cores per node and InfiniBand 1 x 56 Gb/s FDR interconnect. We note, that only the inner \(20\times20\times20\) Solfec-1.0 array was parallelized using MPI; the entire Parmec model (the remaining 19000 bodies) was run on MPI rank 0 process, utilising task based parallelism (in all cases all 24 cores of the single node were used).
CPU cores |
24 |
48 |
96 |
192 |
Runtime [h] |
1.82 |
1.09 |
0.69 |
0.47 |
Animation 4 depicts load balancing of contact points within Solfec-1.0 submodel. The inner \(20\times20\times20\) array generates up to 100k contact points on average, as seen in Fig. 59. Table 29 summarises the minimum, average and maximum numbers of bodies and contact points for 24–192 MPI rank (CPU cores) runs. Solfec-1.0 utilizes a single geometrical partitioning in order to balance together the bodies and the contact points. Contact points are favoured in the load balancing due to the higher computational work related to their processing. Table 30 shows that contact update, detection, solution and assembling of the local dynamics take up the majority of the computational time. The remaining time is spent in load balancing. In this example, Solfec-1.0 solves an implicit frictional contact problem of varying size at every time step. Fig. 59 depicts the time history of the number of contact points over the one second duration of the simulation.
- 4
Solfec-1.0 viewer based animation of load balancing for the 30x30x30 model with N=20. Contact points are colored according to processor rank for the 48 CPU cores based parallel run. Solfec-1.0 utilizes dynamic load balancing in order maintain parallel balance.
CPU cores |
24 |
48 |
96 |
192 |
Body min |
250 |
109 |
49 |
17 |
Body avg |
433 |
216 |
108 |
54 |
Body max |
687 |
383 |
220 |
132 |
Contact min |
1421 |
731 |
394 |
183 |
Contact avg |
1651 |
873 |
485 |
249 |
Contact max |
1874 |
1033 |
609 |
342 |
CPU cores |
24 |
48 |
96 |
192 |
Time integration |
18.0 |
13.8 |
11.0 |
8.8 |
Contact update |
8.3 |
10.3 |
11.4 |
12.7 |
Contact detection |
8.5 |
7.8 |
7.1 |
5.6 |
Local dynamics |
14.6 |
14.3 |
14.1 |
13.3 |
Contact solution |
21.1 |
19.5 |
19.4 |
16.3 |
Load balancing |
29.5 |
34.3 |
36.9 |
43.1 |
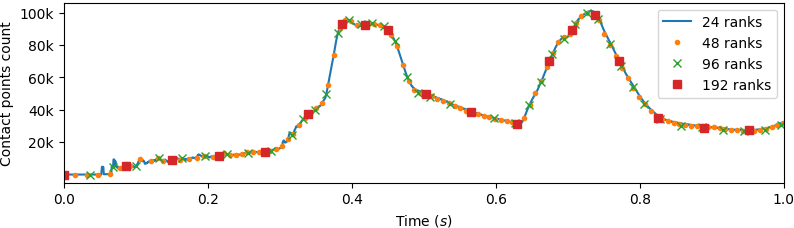
Fig. 59 Example hybrid-solver3 (M=5,N=20): time history of the contact points count.¶